Choose right database


Master Slave Replication: If too much load
Advantage:
Strict consistency (always get correct data).
To achieve consistency we can implement master-slave replication. 1 master for writes because of data consistency and multiple read replicas for reads with load balancing.
Highly available (I need the data right now)
Disadvantage:
Not partition tolerance
Very hard to scale
Single point of failure
Writes are not scaled
Latency because of replication
Sharding: If too much data

Advantage:
- We can scale the write operations
Disadvantage:
Complex queries
May need to access multiple databases to get your data
When to use what?
Master Slave if:
too much load
needs more reads than writes
Sharding if:
- too much data
Brewer's CAP Theorem
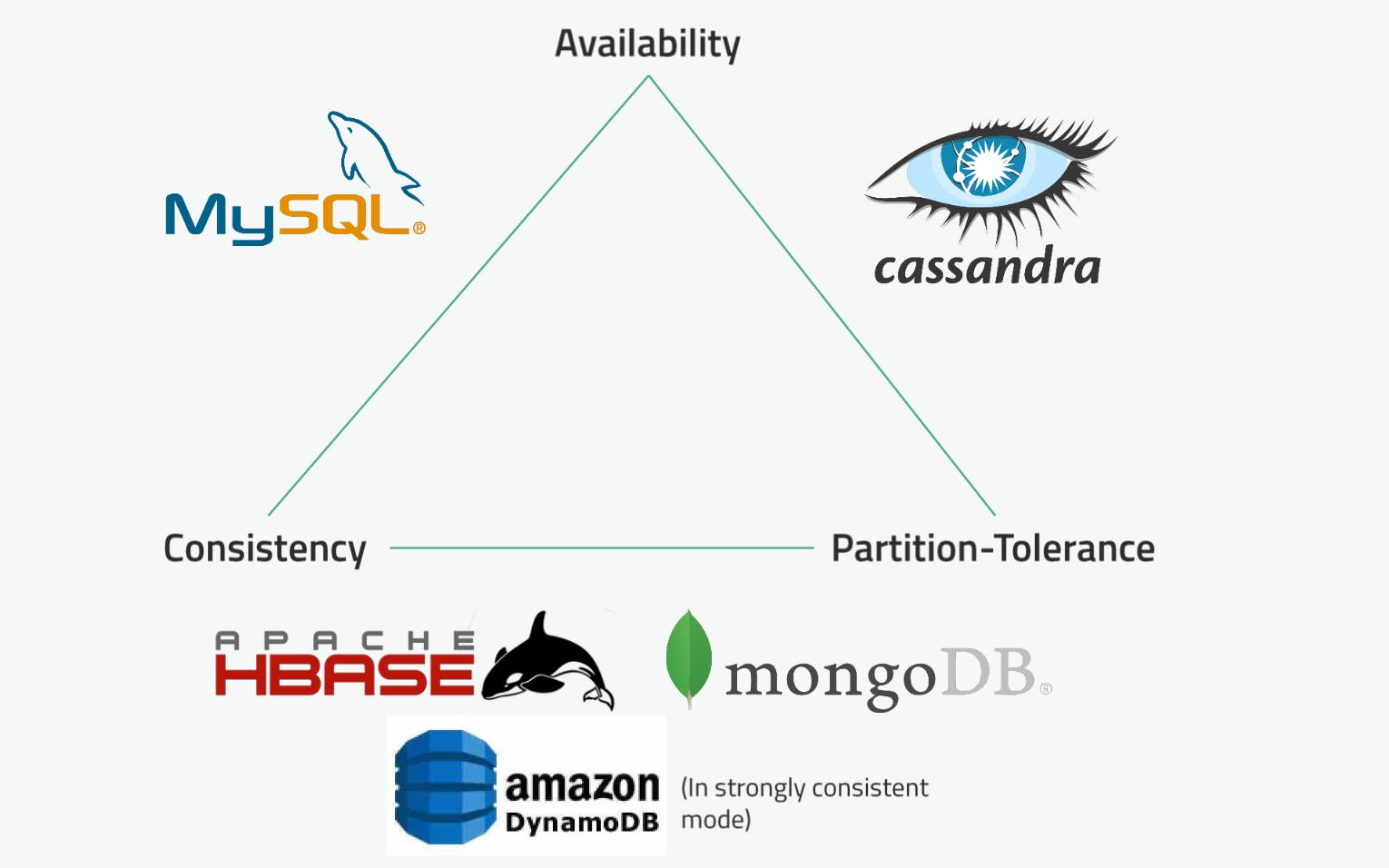
Relational Database: It is very hard to scale
Advantage:
Strict consistency
Highly available
Disadvantage:
Scaling writes is very difficult and limited
Vertical scaling is limited and expensive
Horizontal scaling is limited and complex
The schema is fixed
Does not easily handle unstructured and semi-structured data
NoSQL Database: It is easy to scale (scaling is built-in)
Advantage:
Not fixed schema
Can scale***(almost)***unlimited
Key-value store
Disadvantage:
- Latency because of Eventual consistency.
Key-value store (eg. Redis => Remote Dictionary Service):
Advantage:
Very fast since the in-memory (temporary purpose for example caching) database
Scalable
Use case: If we do not need to query the data rather just get, put or delete. For example: storing session data, shopping cart data, profiles and preferences.
Disadvantage:
- No way to query based on the content of the value
Document Database (eg. MongoDB):
Stores data in BSON
Structure/organize the data according to your queries: Define Queries first and then create collections accordingly.
Advantage:
Fast
Can handle unstructured or semi-structured data (Schema Free)
Disadvantage:
- Data duplication (for example same name field in multiple documents)
[
{
"professor_name": "John",
"student_name": "Bikash"
},
{
"professor_name": "John",
"student_name": "Bimal"
}
]
Column Family Database (eg. Cassandra, DynamoDB):
- Structure/organize the data according to your queries. Define Queries and then create tables accordingly.
Advantage:
Schema Free (each row can have different columns)
Key-value store
Read operation is very fast
Disadvantage:
Write operation is very slow
Data duplication in multiple tables as shown in the picture below

Partition Key:
Composite Key:
Clustering Key:
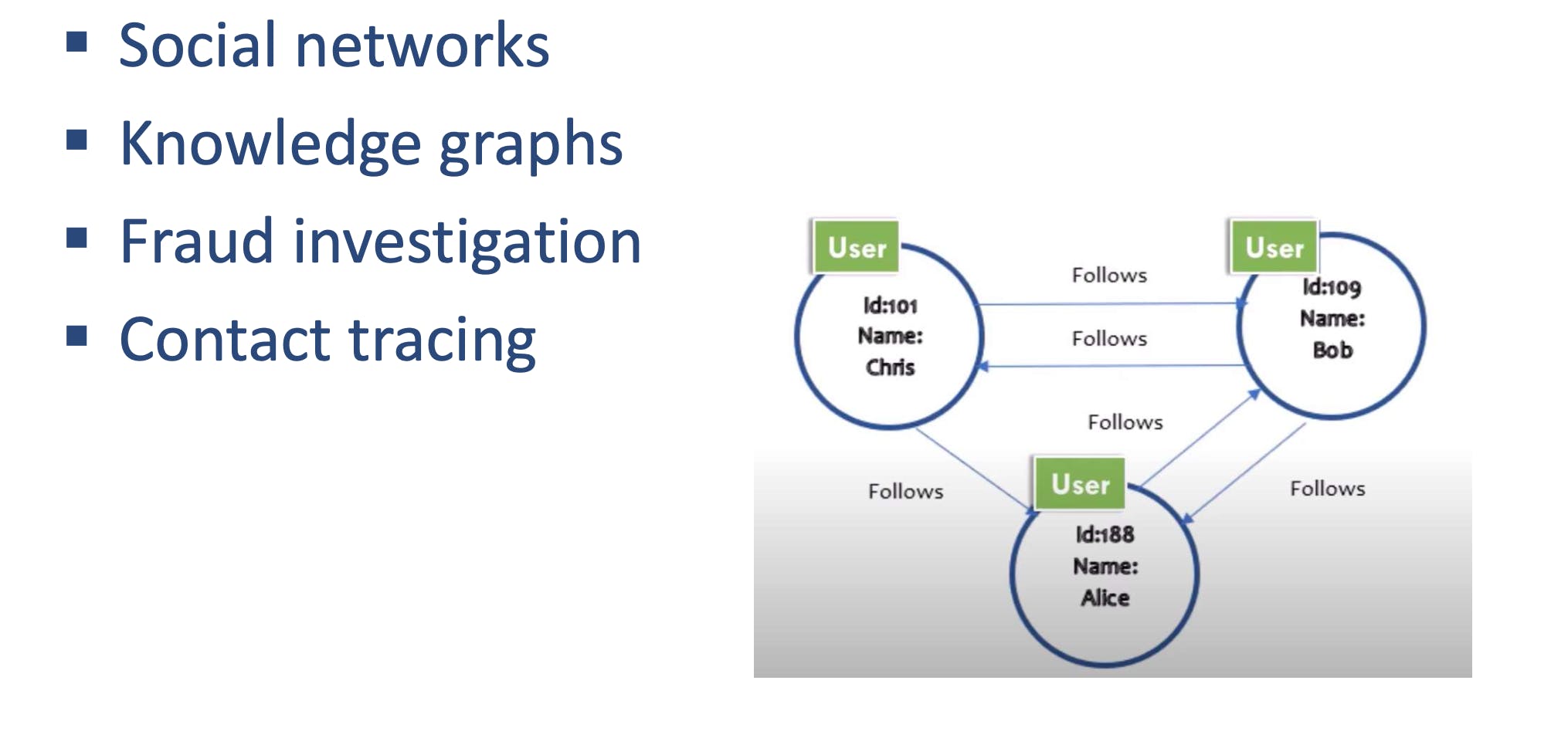
Graph (eg. Neo4j, OrientDB, ArrangoDB): Has only nodes and edges
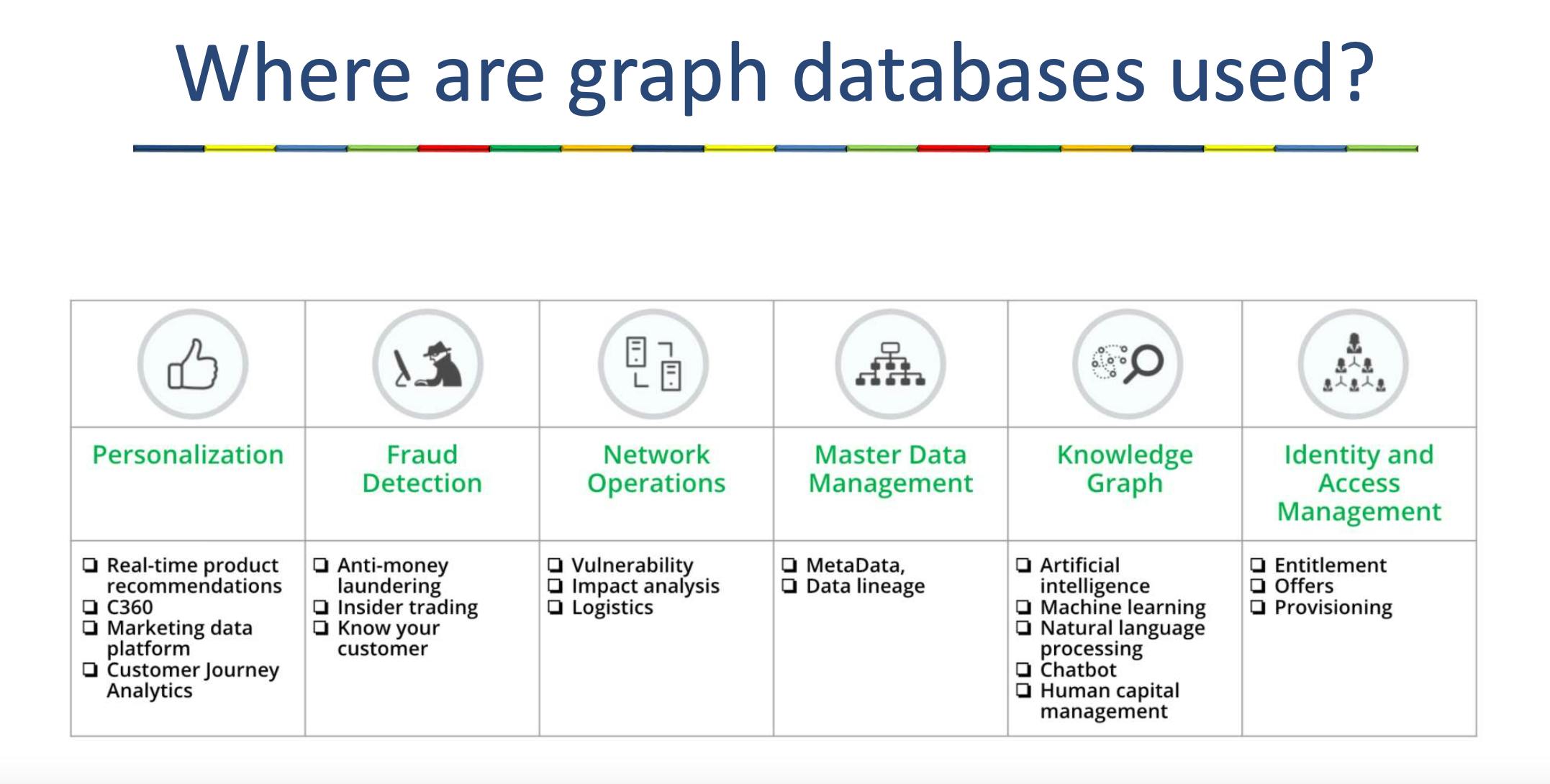
Use Cases:
Advantage:
No joins needed
Very fast in analyzing data
Not fixed schema so easy to evolve dataset as needed
When to use a graph database?
-> When you are interested in relationships between entities(nodes)